68 lines
2.8 KiB
Markdown
68 lines
2.8 KiB
Markdown
sibe
|
|
====
|
|
A simple Machine Learning library.
|
|
|
|
## Simple neural network
|
|
```haskell
|
|
let a = (sigmoid, sigmoid') -- activation function
|
|
-- random network, seed 0, values between -1 and 1,
|
|
-- two inputs, two nodes in hidden layer and a single output
|
|
rnetwork = randomNetwork 0 (-1, 1) 2 [(2, a)] (1, a)
|
|
|
|
-- inputs and labels
|
|
inputs = [vector [0, 1], vector [1, 0], vector [1, 1], vector [0, 0]]
|
|
labels = [vector [1], vector [1], vector [0], vector [0]]
|
|
|
|
-- define the session which includes parameters
|
|
session = def { network = rnetwork
|
|
, learningRate = 0.5
|
|
, epochs = 1000
|
|
, training = zip inputs labels
|
|
, test = zip inputs labels
|
|
} :: Session
|
|
|
|
initialCost = crossEntropy session
|
|
|
|
-- run gradient descent
|
|
-- you can also use `sgd`, see the notmnist example
|
|
newsession <- run gd session
|
|
|
|
let results = map (`forward` newsession) inputs
|
|
rounded = map (map round . toList) results
|
|
|
|
cost = crossEntropy newsession
|
|
|
|
putStrLn $ "- initial cost (cross-entropy): " ++ show initialCost
|
|
putStrLn $ "- actual result: " ++ show results
|
|
putStrLn $ "- rounded result: " ++ show rounded
|
|
putStrLn $ "- cost (cross-entropy): " ++ show cost
|
|
```
|
|
|
|
|
|
## Examples
|
|
```bash
|
|
# neural network examples
|
|
stack exec example-xor
|
|
stack exec example-424
|
|
# notMNIST dataset, achieves ~87.5% accuracy after 9 epochs (2 minutes)
|
|
stack exec example-notmnist
|
|
|
|
# Naive Bayes document classifier, using Reuters dataset
|
|
# using Porter stemming, stopword elimination and a few custom techniques.
|
|
# The dataset is imbalanced which causes the classifier to be biased towards some classes (earn, acq, ...)
|
|
# to workaround the imbalanced dataset problem, there is a --top-ten option which classifies only top 10 popular
|
|
# classes, with evenly split datasets (100 for each), this increases F Measure significantly, along with ~10% of improved accuracy
|
|
# N-Grams don't seem to help us much here (or maybe my implementation is wrong!), using bigrams increases
|
|
# accuracy, while decreasing F-Measure slightly.
|
|
stack exec example-naivebayes-doc-classifier -- --verbose
|
|
stack exec example-naivebayes-doc-classifier -- --verbose --top-ten
|
|
```
|
|
|
|
### notMNIST
|
|
|
|
notMNIST dataset, sigmoid hidden layer, cross-entropy loss, learning rate decay and sgd ([`notmnist.hs`](https://github.com/mdibaiee/sibe/blob/master/examples/notmnist.hs)):
|
|
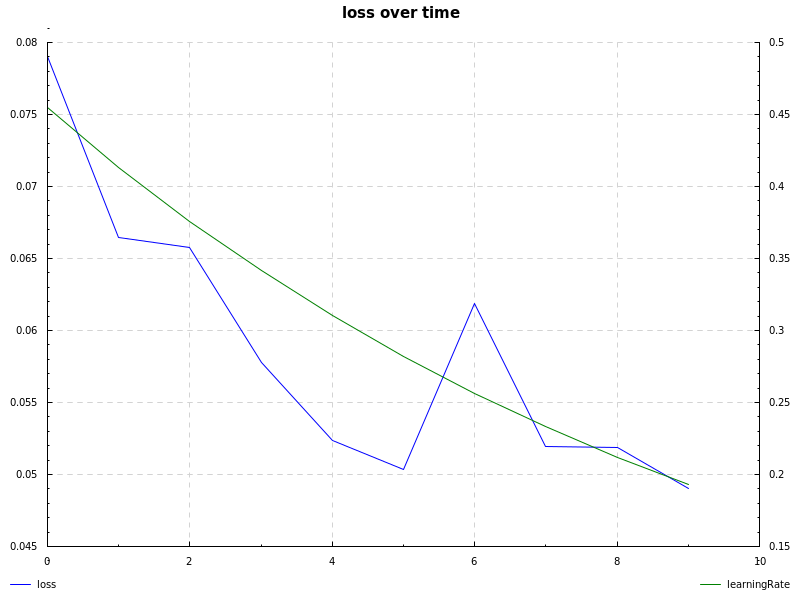
|
|
|
|
notMNIST dataset, relu hidden layer, cross-entropy loss, learning rate decay and sgd ([`notmnist.hs`](https://github.com/mdibaiee/sibe/blob/master/examples/notmnist.hs)):
|
|

|