{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
sibe
A simple Machine Learning library.
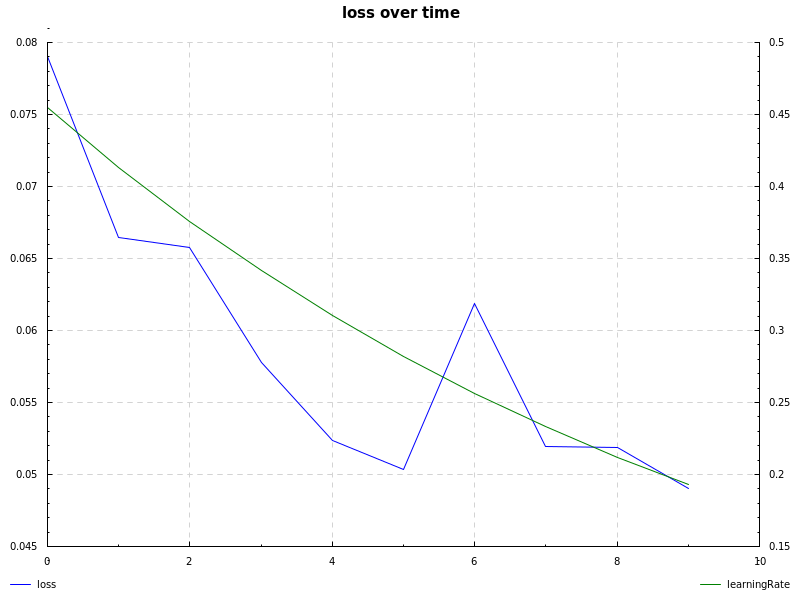
notMNIST dataset, cross-entropy loss, learning rate decay and sgd:
See examples:
# neural network examples
stack exec example-xor
stack exec example-424
# notMNIST dataset, achieves ~87% accuracy using exponential learning rate decay
stack exec example-notmnist
# Naive Bayes document classifier, using Reuters dataset
# using Porter stemming, stopword elimination and a few custom techniques.
# The dataset is imbalanced which causes the classifier to be biased towards some classes (earn, acq, ...)
# to workaround the imbalanced dataset problem, there is a --top-ten option which classifies only top 10 popular
# classes, with evenly split datasets (100 for each), this increases F Measure significantly, along with ~10% of improved accuracy
# N-Grams don't seem to help us much here (or maybe my implementation is wrong!), using bigrams increases
# accuracy, while decreasing F-Measure slightly.
stack exec example-naivebayes-doc-classifier -- --verbose
stack exec example-naivebayes-doc-classifier -- --verbose --top-ten